
Startup将1000个RISC-V内核封装到AI加速器芯片中
这家初创公司的节能芯片以M.2加速器插座为目标,用于加速数据中心的推荐模型。 恰逢热门芯片大会,初创公司世界语本周从隐形模式中脱颖而出,推出了迄今为止性能最高的商用RISC-V芯片——一款专为超大规模数据中心设计的千核人工智能加速器。虽然该...
这家初创公司的节能芯片以M.2加速器插座为目标,用于加速数据中心的推荐模型。
恰逢热门芯片大会,初创公司世界语本周从隐形模式中脱颖而出,推出了迄今为止性能最高的商用RISC-V芯片——一款专为超大规模数据中心设计的千核人工智能加速器。虽然该芯片可以在10到60 W之间的多个电压和功率分布中运行,但其“最佳点”是每个芯片20 W的功率,这种配置允许在Glacier Point加速器卡上安装六个芯片,使总功耗保持在120 W以下。六个芯片的总性能约为800 TOPS。
世界语公司的ET-SoC-1被称为拥有有史以来在单个芯片上构建的最多RISC-V内核:1093。这一数字包括1088个ET Minion定制RISC-V内核,这些内核可以作为节能的人工智能加速引擎。还包括四个ET Maxion RISC-V内核和一个RISC-V服务处理器。整个设计都是为了提高能源效率。
在热芯片之前,EE时间与世界语创始人兼执行主席、业内资深人士戴夫·迪策尔进行了交谈。(Ditzel的资历包括与David Patterson共同撰写这篇开创性的论文,”精简指令集计算机案例”1980年出版。)

<img data-lazy-fallback="1" decoding="async" src="https://uploads.9icnet.com/images/aritcle/20230418/Dave-Ditzel-Esperanto.jpg">
Dave Ditzel(资料来源:世界语)
Ditzel说:“我们是第一个在单个芯片上安装一千个RISC-V内核的公司。”。“多年来,人们一直在谈论许多核心CPU,但我们还没有看到太多。市面上大多数RISC-V都是嵌入式的。
“我们说,‘让我们向他们展示RISC-V可以做高端……我们将向他们展示真正经验丰富的CPU设计师可以在这里做什么’。”
客户要求
Ditzel的CPU设计师团队能够从超大规模数据中心运营商那里梳理出有关其需求的细节。
迪策尔说:“他们不想要训练芯片,他们在训练方面没有问题。”。人工智能训练通常是一个离线问题,超缩放器巨大的x86 CPU容量并不总是处于峰值负载。因此,这种能力可以在可用时用于培训。“他们真正的问题是推理,”迪策尔补充道。“这就是他们广告的驱动力。他们需要在10毫秒或更短的时间内得到答案。”
因此,加速在线广告的推荐推理引擎成为数据中心芯片的一个重点。超缩放器对加速这类模型的要求相当明确。
他说:“我们的客户想要100兆字节的片上内存——他们想做的所有推理都能容纳100兆字节。”。客户还想要一个用于芯片外存储器的外部接口。Ditzel解释道:“真正的问题是你能持有多少加速器卡。”。“把卡想象成计算单元,而不是芯片。一旦你能在卡上获得内存,你就可以比通过PCIe总线访问主机更快地访问东西。”

<img data-lazy-fallback="1" decoding="async" src="https://uploads.9icnet.com/images/aritcle/20230418/Esperanto-Glacier-Point.jpg">
世界语在冰川点加速器卡上安装了六张双M.2卡,每张卡都有一个芯片。(资料来源:世界语)
片上存储器系统具有L1、L2和L3高速缓存,以及带有寄存器堆的完整主存储器系统,总容量略高于100MB。卡上存储系统可以在大约100 GB的空间内容纳模型中的大多数重量和激活。
众所周知,推荐模型很难加速,这也是它们仍然在现有CPU服务器上运行的原因之一。
迪策尔说:“当你从1亿客户中挑选他们最近购买的东西时,你必须访问卡上的内存,并且你要进行各种随机内存访问,所以缓存不起作用。你真的需要更多的经典电脑。”。“x86服务器可以处理大量内存,而且它们具有预取功能,通用CPU可以很好地处理这种工作负载。因此,任何加速器都很难进入推荐业务。”
还需要支持INT8以及FP16和FP32数据类型。对浮点数学的要求既源于需要保持尽可能高的预测精度,也源于缺乏移植或重写低精度数学程序的倾向。Ditzel表示,领先的x86服务器芯片制造商最近才为服务器CPU添加了8位矢量扩展。
他说:“在百万台x86服务器上的(超规模数据中心)中,大多数推理仍然是32位浮点的。”。
世界语的双M.2卡芯片设计用于安装现有x86 CPU服务器基础设施中的加速器插槽。这导致功率限制为120W,需要空气冷却。
迪策尔表示,世界语的设计与诸如谷歌TPU或亚马逊网络服务的推理超级规模公司“正试图让整个社区为他们制造加速器芯片。这些公司中的很多都相信开放计算和[开放计算项目]。”因此,“他们购买OCP服务器,并希望在那里使用标准化的东西。如果有竞争,他们会喜欢……他们试图鼓励竞争,向人们展示什么是可能的。”
尽管如此,这家初创公司坚持认为,大数据中心运营商需要加速器芯片的外部供应商。“这仍然是一个决定是否购买的决定。”例如,一位世界语客户无法获得另一个部门正在使用的内部开发的芯片。“如果你击败了他们,进入这些公司中的任何一家都是可能的。”
新方法
世界语采取了与竞争对手的巨型耗电芯片加速器相反的方法,提供了一种可以多次使用的低功耗芯片。该方法解决了内存带宽需求,因为更多的引脚可以用于内存I/O,而不必花费昂贵的成本血红蛋白.
世界语的硬件也被设计成一台通用计算机;Ditzel表示,尽管重点关注推荐模型,但该芯片可以加速并行处理。一个六芯片加速卡包括大约6000个并行内核,每个内核可以执行两个线程,这可以“针对任何任意问题”
世界语的另一个诀窍是积极的节能设计。客户要求将总功率预算设置为120 W,而Glacier Point卡上建立的最大空间为6个芯片,即每个芯片20 W。相比之下,人工智能推理加速器的运行速度是这个数字的十倍多。
世界语从几个角度解决了这个问题。时钟频率被降低到大约1GHz的最佳水平。电源电压降低到0.4V左右,超出了SRAM的限制。通过使用具有最小商业可行指令集的精简RISC-V内核来减少晶体管的数量,从而有助于开关电容。选择了一种先进但稳定的工艺技术,台积电7nm。

<img data-lazy-fallback="1" decoding="async" src="https://uploads.9icnet.com/images/aritcle/20230418/Voltage-performance-graph-Esperanto-chip.jpg">
世界语确定了一个在1GHz左右工作的“最佳点”。(资料来源:世界语)
核心设计
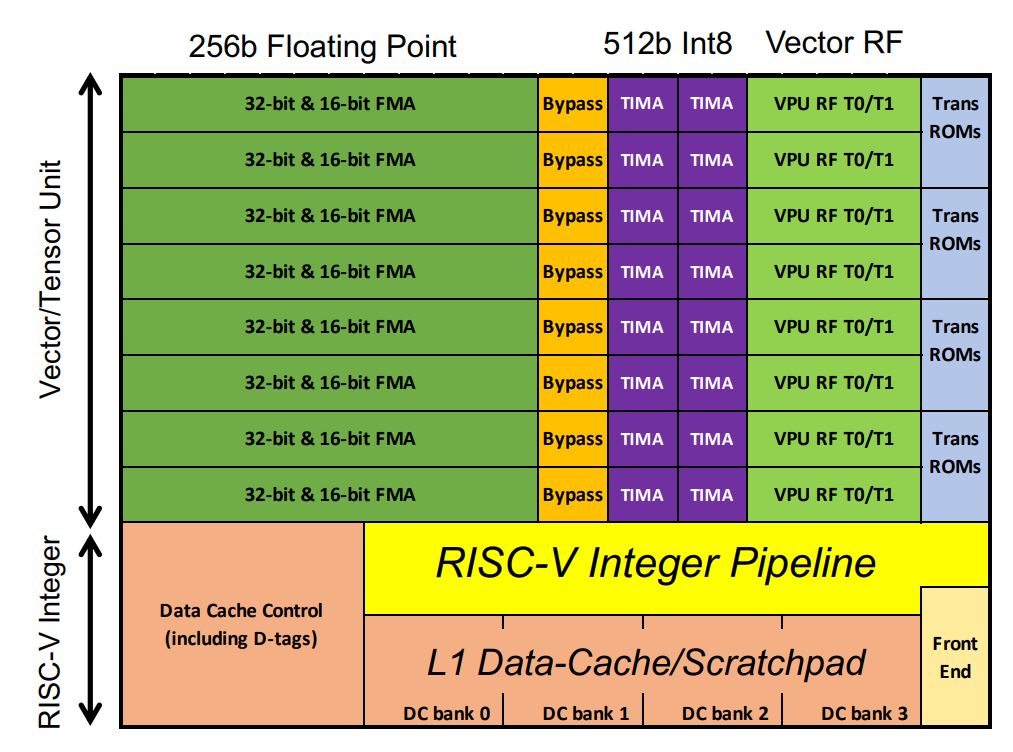
世界语的芯片包括1088个ET Minion核心,用于处理人工智能工作负载。核心是64位、有序的RISC-V处理器,世界语自己的AI优化向量和张量单元占据了芯片的大部分空间。浮点MACs主导配置。不同寻常的是,整数MAC的处理宽度是浮点的两倍(根据客户要求,Ditzel指出)。还支持向量超越指令,如深度学习模型中常见的sigmoid函数。由于内核运行在单个低电压域中,因此在小型L1高速缓存中使用了更多的晶体管和SRAM,以确保稳健的性能。
<img data-lazy-fallback="1" decoding="async" src="https://uploads.9icnet.com/images/aritcle/20230418/ET-Minion-core-diagram.jpg">
世界语的芯片包含1088个ET迷你核心(点击图片放大)(来源:世界语)
每个核心能够每千兆赫128个GOPS。自定义多循环张量指令执行大型矩阵乘法,其中单独的控制器接管并使用整个512位宽运行多达512个循环。这允许单个张量指令在控制器获取下一条RISC-V指令之前执行64000多次算术运算。这减少了指令带宽,因为大部分工作负载都使用张量指令。因此,每512个时钟周期只需要一条指令。
八个ET Minion核心构成了一个“邻域”,修改后的指令利用了它们的物理邻近性。另一个被称为“协作加载”的功能允许内核在没有缓存提取的情况下直接相互传输数据。这种配置可以节省电力。八个核心还共享一个大的L2高速缓存以提高能源效率。
再次缩小,四个8核社区组成了一个“迷你郡”,每个芯片上有34个郡,总共1088个核。(Ditzel说,只使用1024个核来提高产量也是可能的)。四个ET Maxion核心,每个核心的性能大致相当于Arm A-72,旨在用于未来的独立操作,而不是当前的加速器配置。
通过为每个夏尔提供自己的电压源,可以对各个电压进行微调,从而减轻阈值电压的变化。
内存系统
每个芯片有四个64位DDR接口——实际上,每个接口代表四个16位通道——总共96 x 16位通道。该设计使用LPDDR4x作为智能手机的低功耗存储器。每比特的能量大致相当于HBM,但将六芯片加速卡的存储器接口上的总能量保持在1536比特会产生更高的总存储器带宽。
世界语将其芯片安装在双插槽M.2卡上;六个可安装在OCP Glacier Point v2加速器卡上(前三个,后三个)。这提供了大约800个TOPS,芯片运行频率为1GHz。它们也可以安装在薄型(半高、半长)PCIe卡上,将每个芯片的功率预算增加到60 W左右。根据应用,芯片可以在300 MHz和2 GHz之间工作。
根据硬件仿真结果,Ditzel断言Glacier Point卡上的六个世界语芯片可以胜过竞争对手。当考虑到内存系统设计和每瓦性能数据时,这家初创公司的优势在推荐基准测试中是显而易见的,这是对低电压设计的关注的结果。
未来的版本可能包括用于边缘应用的ET-SoC-1的缩小版本。迪策尔表示,目前的版本应该在“未来几个月”内推出。
>>这篇文章最初发表在我们的姐妹网站上,EE时间.